Flashblocks: Deep Dive - 250ms preconfirmations on OP Mainnet
Onchain applications live and die by their user experience. If transactions feel slow or unpredictable, the promise of Ethereum scalability falls flat. This is where Flashblocks come in, a streaming block-construction layer built by Flashbots and now deployed to Optimism’s OP Mainnet. Instead of waiting for the standard 2-second block time, Flashblocks break blocks into smaller chunks and emit them every 250 milliseconds. This creates a flow of preconfirmations - strong signals that a transaction will be included - giving users and apps near-instant feedback.
Why does this matter? Because user experience wins. When transactions feel instant, applications become more engaging and trustworthy. DeFi traders can react quickly, games can update responsively, and social apps feel snappy.
In this post, we’ll walk through how Flashblocks work, our infrastructure setup, the reliability and safety guardrails we added, and the performance improvements we implemented to make them production-ready.
How Flashblocks Work
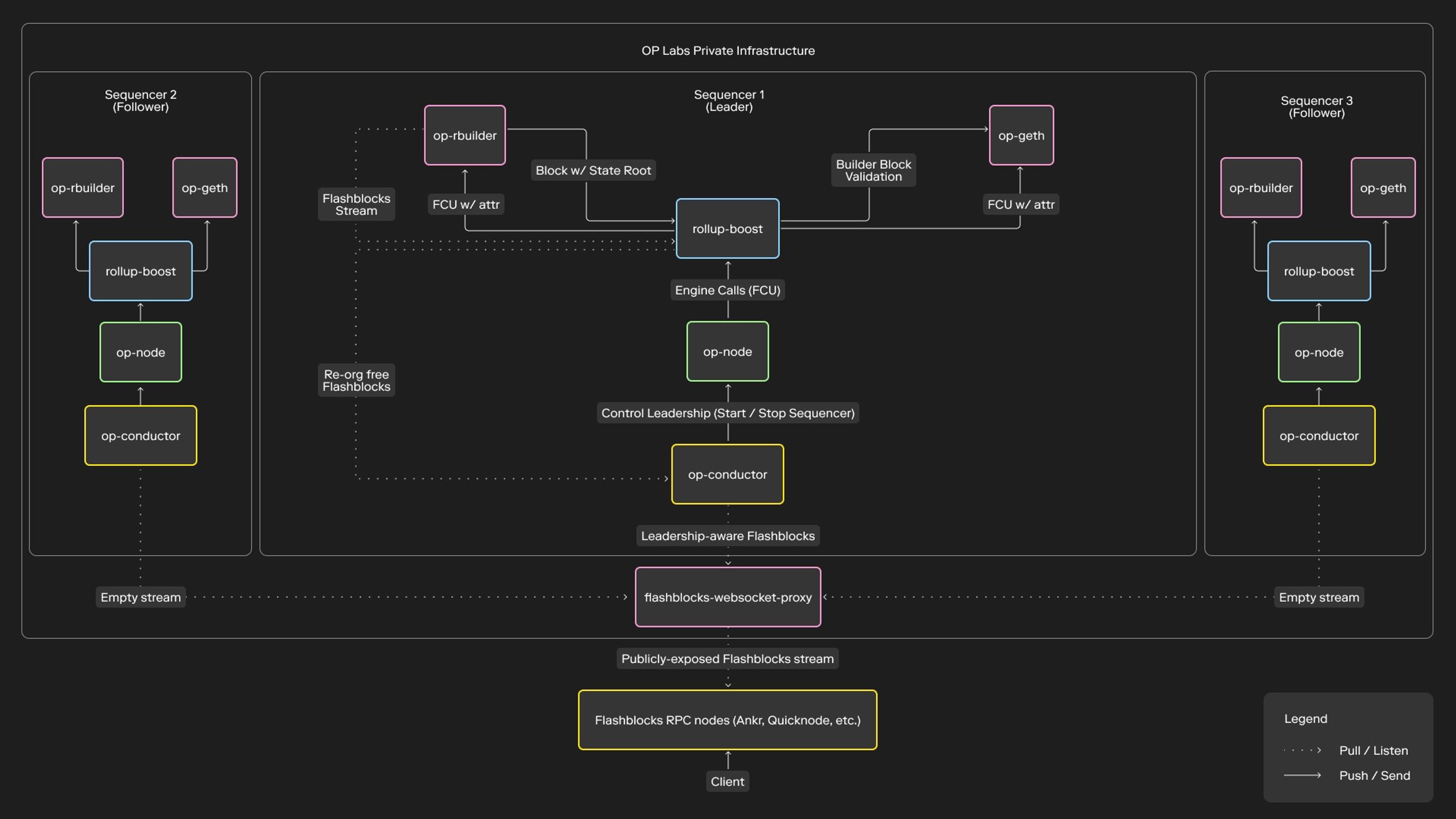
At its core, Flashblocks reimagine how transactions flow through OP Mainnet. In the traditional model, the sequencer builds a single block every 2 seconds. Until that block is produced, users don’t know if their transaction will be included.
Flashblocks break this waiting game by introducing streaming block construction. Instead of holding everything back until the block is finalized, these logical sub-blocks are emitted every 250ms. Each Flashblock contains a portion of the transactions that will eventually be part of the canonical block. Other nodes can start executing these transactions immediately, and users see their actions reflected almost instantly.
The final block is still produced every 2 seconds, complete with the correct state root and all consensus guarantees. Flashblocks don’t replace finality - they layer a UX-level preconfirmation system on top of it.
Optimism’s Infrastructure Setup
Introducing Flashblocks required carefully designing an infrastructure that could handle streaming blocks without breaking protocol correctness. The goals were clear:
- Near-instant UX without protocol changes: Keep the underlying contracts untouched
- Safety by construction: Always validate against a canonical builder (geth)
- Leader-aware propagation: Only the active sequencer can emit Flashblocks
- Stable developer surface: Expose Flashblocks through standard JSON-RPC
Core Components
To achieve this, several components were introduced or adapted:
op-node(consensus client): Unmodified. Issues Engine API calls and remains unaware of Flashblocks.op-geth(execution client): Acts as the canonical builder and validation fallbackop-rbuilder(modified reth based execution client): Builds canonical blocks and emits Flashblocks at a 250ms cadencerollup-boost: Mediates betweenop-nodeand the execution clients, validatingop-rbuilderoutputs againstop-gethand selecting the trusted sourceop-conductor: Manages sequencer orchestration, ensuring that only the current leader forwards Flashblocksflashblocks-websocket-proxy: Provides a stable WebSocket endpoint by listening to all conductors but forwarding only the leader’s stream- Flashblocks-aware RPC node: Subscribes to the proxy and augments
eth_getBlockByNumber("pending")with sub-block updates
Control Plane
Deployment is controlled through three modes in rollup-boost:
- Off: No Flashblocks. All engine calls are forwarded to only
op-geth. - Dry Run: Shadow validation. Engine calls forwarded to both
op-rbuilderandop-gethbut only op-geth’s payloads are accepted. Divergences are logged for analysis. - On: Production mode.
op-rbuildertreated as the primary block builder where its payloads are used and cross-checked againstop-geth, with automatic fallback if needed.
Data Plane
Once Flashblocks are active, the data flow looks like this:
op-rbuilderemits Flashblocks at 250ms intervals (note that the interval is configurable)rollup-boostfilters out stale / re-orged Flashblocks listened from op-rbuilder and forwards the remaining ones. Validates the payloads returned byop-rbuilderagainstop-gethop-conductorlistens to the Flashblocks from rollup-boost and forwards them further only if its sequencer is leader.flashblocks-websocket-proxyaggregates Flashblocks from leader streams and exposes a single stable endpoint- RPC nodes consume the stream and update the pending block view every 250ms
This architecture ensures Flashblocks can be safely streamed without exposing users to conflicting or stale data.
Reliability and Safety
Fast confirmations are only useful if they are trustworthy. A preconfirmation that disappears later would destroy user confidence. This is tackled with several guardrails.
Re-org Safety
One challenge is preventing Flashblocks from “leaking” after they’ve been realised to have stale payload_ids or to be re-orged out. To solve this, rollup-boost tracks payload IDs tied to each Flashblock. If a Flashblock belongs to a block (payload) that has already been invalidated, it is discarded before reaching clients. This guarantees that users never see phantom preconfirmations.
Leader-Aware Forwarding
Since multiple sequencers exist, only one can be the leader at any time. op-conductor enforces this by forwarding Flashblocks only when its sequencer holds leadership. If leadership changes, the newly setup leader starts generating and forwarding Flashblocks while the previous one stops. This helps tackle split-brain scenarios where multiple op-rbuilders (hence, rollup-boost) might emit Flashblocks despite their non-leader status.
Validation and Fallback
To have additional confidence in block building, op-rbuilder generated payload must be cross-checked against op-geth. If it diverges or lags beyond a threshold, rollup-boost immediately switches payloads back to op-geth. Users still see reliable block data, just without Flashblocks until the builder recovers.
Operational Hardening
Finally, the system was built to resist operational failures and DoS attacks. Flashblocks proxies are horizontally scaled and rate-limited. Provider-specific proxies (for QuickNode, Ankr, etc.) require API keys, isolating tenants and preventing noisy neighbors from overwhelming the system.
The result is a safety net where Flashblocks enhance UX without ever undermining the canonical guarantees of OP Mainnet.
Performance Enhancements
Deploying Flashblocks at scale revealed multiple bottlenecks, each of which required targeted solutions.
Disk I/O
op-rbuilder is I/O intensive, and standard SSDs couldn’t keep up. Latency caused missed Flashblock intervals. To fix this, op-rbuilder was deployed on NVMe-backed hosts. An internal snapshot/restore tool was also built to take consistent snapshots and quickly spin up new nodes, making rollouts and incident recovery far faster.
Mempool Handling
Load testing with Flashbots’ Contender revealed spikes in pending transactions on op-rbuilder. Due to this, it even produced empty blocks while user transactions sat waiting. This was traced back to differences in mempool defaults between reth and geth. By tuning parameters such as txpool.max-account-slots and txpool.max-new-pending-txs-notifications, the mempool now processes bursts more smoothly, keeping block builders busy.
Empty Block Prevention
In rare cases, despite the previous fix, op-rbuilder could still produce nearly empty blocks while op-geth produces the same blocks with transactions. To prevent this, the block selection policy, called “gas-used”, was added. It works by ensuring that if an op-rbuilder generated block uses less than 10% of the gas as compared to the op-geth generated block, rollup-boost discards it in favor of op-geth’s block. This eliminated the “empty block” edge case.
Timeouts
Considering our network topology, the default BUILDER_TIMEOUT and L2_TIMEOUT values (1000ms) were too aggressive for Flashblocks’ streaming cadence. They caused false errors and retries. By raising these timeouts to values tailored to our topology, timeout-related errors were nearly eliminated without sacrificing responsiveness.
Leader-Aware Forwarding
To guard against rare split-brain scenarios where multiple op-rbuilders produce Flashblocks at a time, op-conductor was augmented, in collaboration with Base, to listen to Flashblocks from op-rbuilder via rollup-boost, and forward them only when its sequencer is leader. This ensures the proxy sees exactly one authoritative stream, even if other builders continue producing locally.
Mempool Rebroadcaster
Another subtle issue arose from differences between op-geth and op-rbuilder in transaction acceptance. Sometimes a transaction accepted by geth was rejected by rbuilder, leading to delays in inclusion. A mempool rebroadcaster, contributed by Base, now runs periodically to diff the two mempools and re-insert missing transactions into op-rbuilder. This self-healing mechanism improves consistency and reduces dropped transactions.
Boot and Sync Safety
Finally, syncing new op-rbuilder nodes from genesis was painfully slow. To fix this, a snapshot of an existing NVMe-backed node can now be restored onto new hosts. A dedicated op-node-rbuilder is then used to sync via the “consensus layer” syncmode rather than the “execution-layer syncmode”, greatly accelerating the process. During this period, rollup-boost runs in off mode to avoid causing “execution-layer” sync to be triggered by its FCU calls.
Together, these improvements allow Flashblocks to sustain a reliable 250ms cadence under real-world conditions while minimizing operational risks.
Measured Impact
- Pending transaction pool stability
- Before: frequent spikes up to 4,000 txs; sustained plateaus around 1,000.
- After: baseline around ~60 txs with occasional spikes to ~100.
- Impact: ~94% reduction in steady-state backlog (1,000 → 60) and 97.5% reduction in worst-case spikes (4,000 → 100).
- Flashblocks re-org exposure
- Before: 600+ re-orged Flashblocks surfaced over a 10-day window.
- After: 0 exposed (filtered at
rollup-boost). - Impact: 100% prevention of user-visible re-org Flashblocks.
op-rbuilderbacking storage- Before (network-attached SSDs): sporadic block-time degradation to 2.5–3.0 s.
- After (NVMe-backed hosts): near-100% healthy chain and block progression at target cadence.
op-rbuilderspin-up and sync- Before: days to weeks to recover from scratch.
- After: <8 hours via NVMe snapshot + restoration + consensus-layer catch-up.
- Impact: Order-of-magnitude faster recoveries and safer rollouts.
Conclusion
Taken together, these changes move Flashblocks from a promising prototype to a production-hardened path.
Leader-aware forwarding, re-org filtering at rollup-boost, and the gas-used fallback eliminate the primary failure modes such as reorged Flashblocks, empty blocks, and mempool drift, while NVMe I/O, tuned txpool parameters, and right-sized timeouts sustain the 250 ms cadence under real load.
Operationally, snapshot/restore, dual-instance proxying, and mempool rebroadcasting cut recovery time and reduce incident blast radius. The result is a system that is faster, safer, and simpler to operate without asking clients to change how they use JSON-RPC.
Bringing faster UX to the Superchain
Flashblocks bring a step-change improvement to OP Mainnet - by streaming preconfirmations every 250ms, they transform UX across DeFi, gaming, and social applications - all without protocol-level changes. For developers, this means designing apps around the assumption of immediate feedback. Trades settle faster, games feel smoother, and users stay engaged.
This is only the beginning. Over the next few months, we will be testing lower flashblock times and platformizing this setup to bring to the entire Superchain. If you're thinking about deploying an app or launching a chain, learn more about how Optimism's high-performance features can help accelerate your vision.
Authored by

Yashvardhan Kukreja